I consider this to be always in progress. Every few months, a new machine learning model make the previous model somewhat obsolete. This is a reverse-chronological log of my exploration with using machine learning image generation models to make or modify architectural drawings.
Stable Diffusion
These are experiments in using Stable Diffusion first as a text-to-image generator, and then as an image-to-image pipeline. Essentially, a kind of image style transfer using text prompts.
I’m using this huggingface/diffusers repository: https://github.com/huggingface/diffusers















StyleGAN2-ADA
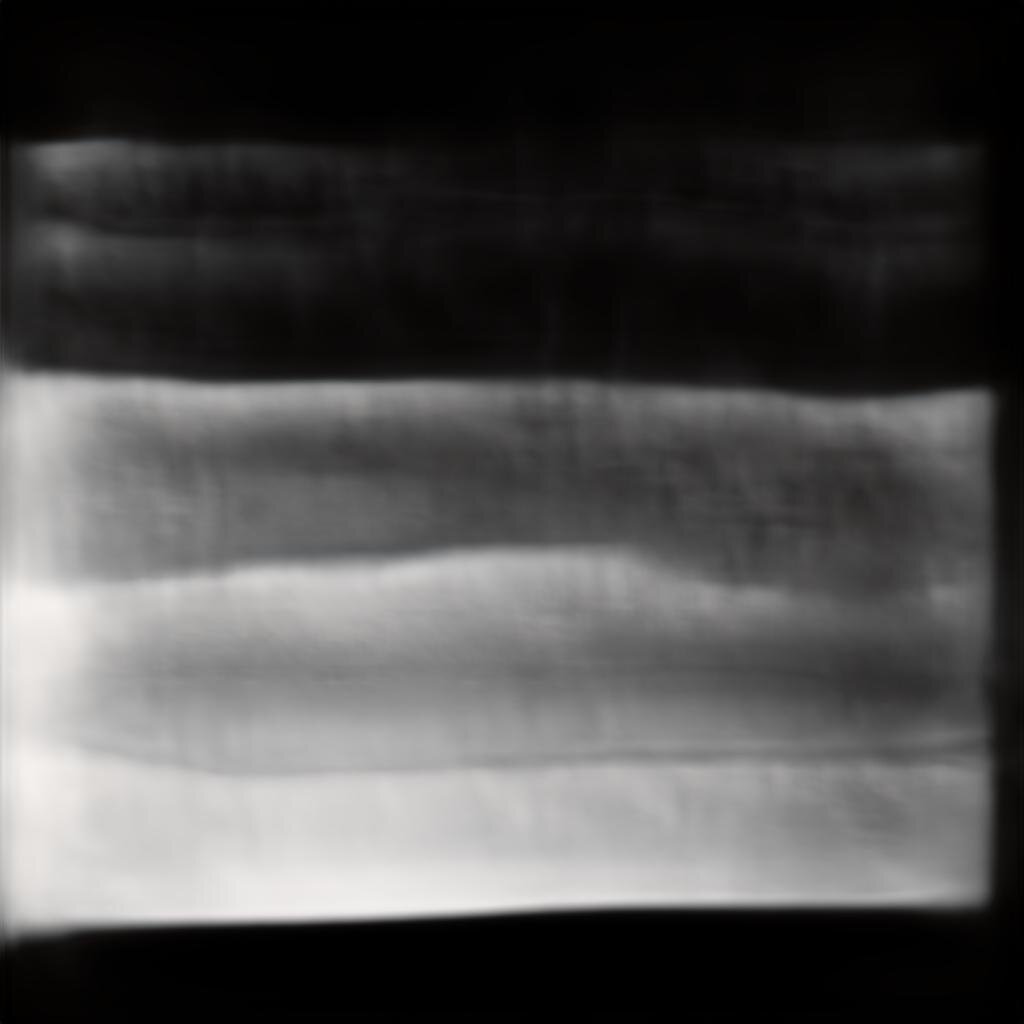
The following were trained for about 16 hours with the StyleGAN2-ADA network. This is a recent update that produces similar results to StyleGAN2, but with much fewer images required in the data set. This is good for an architectural drawing data set like this, when I’m trying to be selective about picking strong compositions to include. The data set is 750 architectural drawings, similar to the previous collection. The images below are from a truncation range between 0.6 and 0.8. A truncation of 0 produces the most common, or most average of all results in the model’s latent space, and a value of 1 or higher produces more unrealistic or abstract results.















StyleGAN2
These images were made with StyleGAN2, a generative adversarial network (GAN) introduced by Nvidia. The model was trained for about 24 hours on a data set of about 1,000 architectural drawings that included several different authors, perspectives, and rendering styles. The results of this model tend to resemble section or elevation drawings, with columns and beams, light and shadow, and a distinct horizon line. As is, the model produces striking compositions, if not very substantive drawings. For training future models, it may be best to separate drawings by their type, and have separate models for perspectives, axonometrics, plans, etc. This is a first step in exploring the limits of neural networks for producing designs and drawings.




















StyleGAN2-ADA + Pix2PixHD
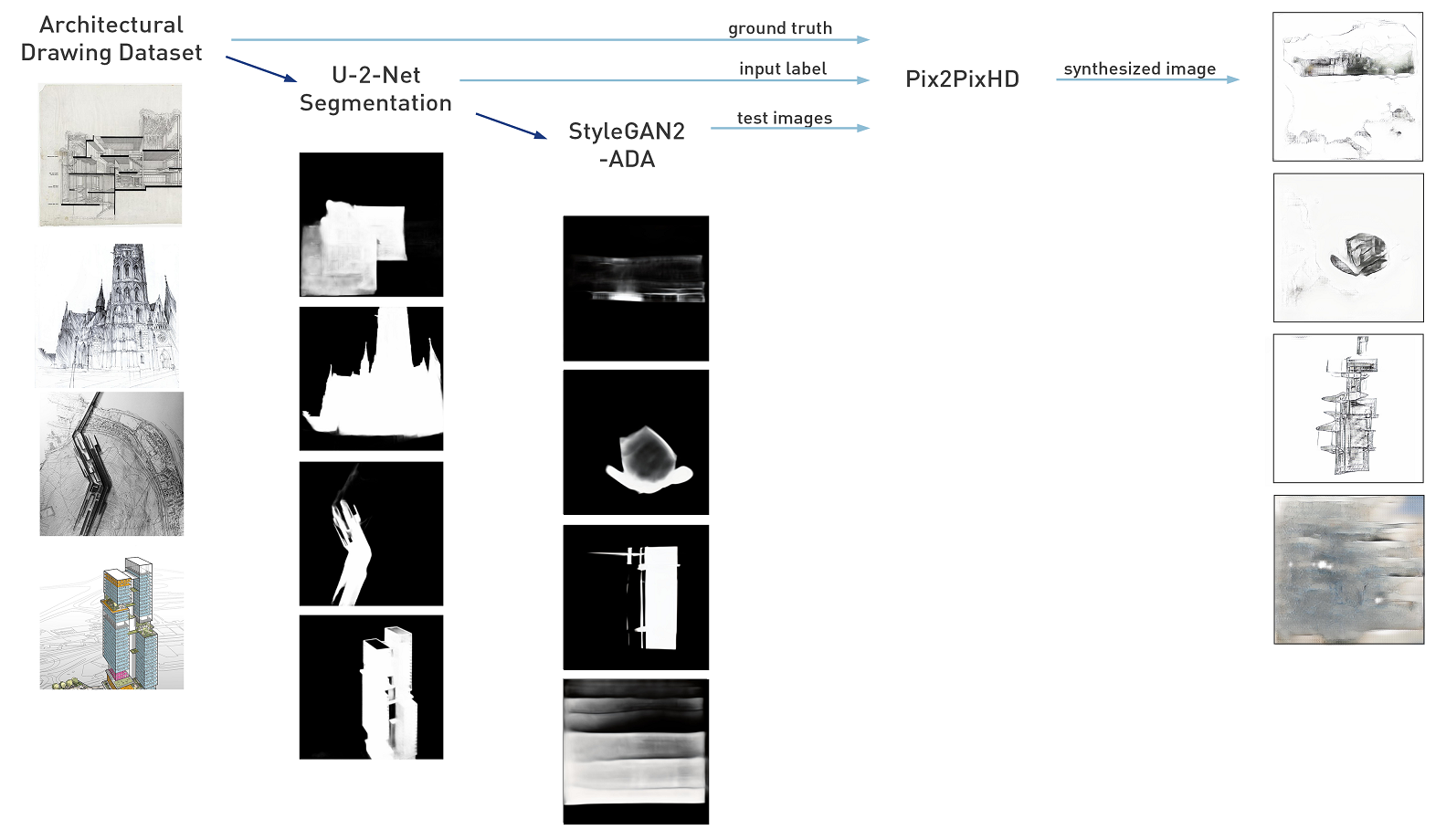
StyleGAN2 can produce strong compositions, but the results are still missing a practical structure or apparent purpose that you would get from a human-made drawing. There’s no true concept of space, depth, or objects. Not without a lot of imagination. My next goal is to combine a StyleGAN model with a Pix2Pix model to get more ‘thoughtful’ results. I used an object segmentation architecture called U^2-Net to make a black and white mask of a few thousand architectural drawings. These black and white masks were put into StyleGAN2-ADA to produce original black and white masks (a few pictured below).



A Pix2PixHD model was trained with the original architectural drawings as the ground truth, the U^2-Net masks as the input label, and the new masks from StyleGAN as the test images. This resulted in the synthesized images below.
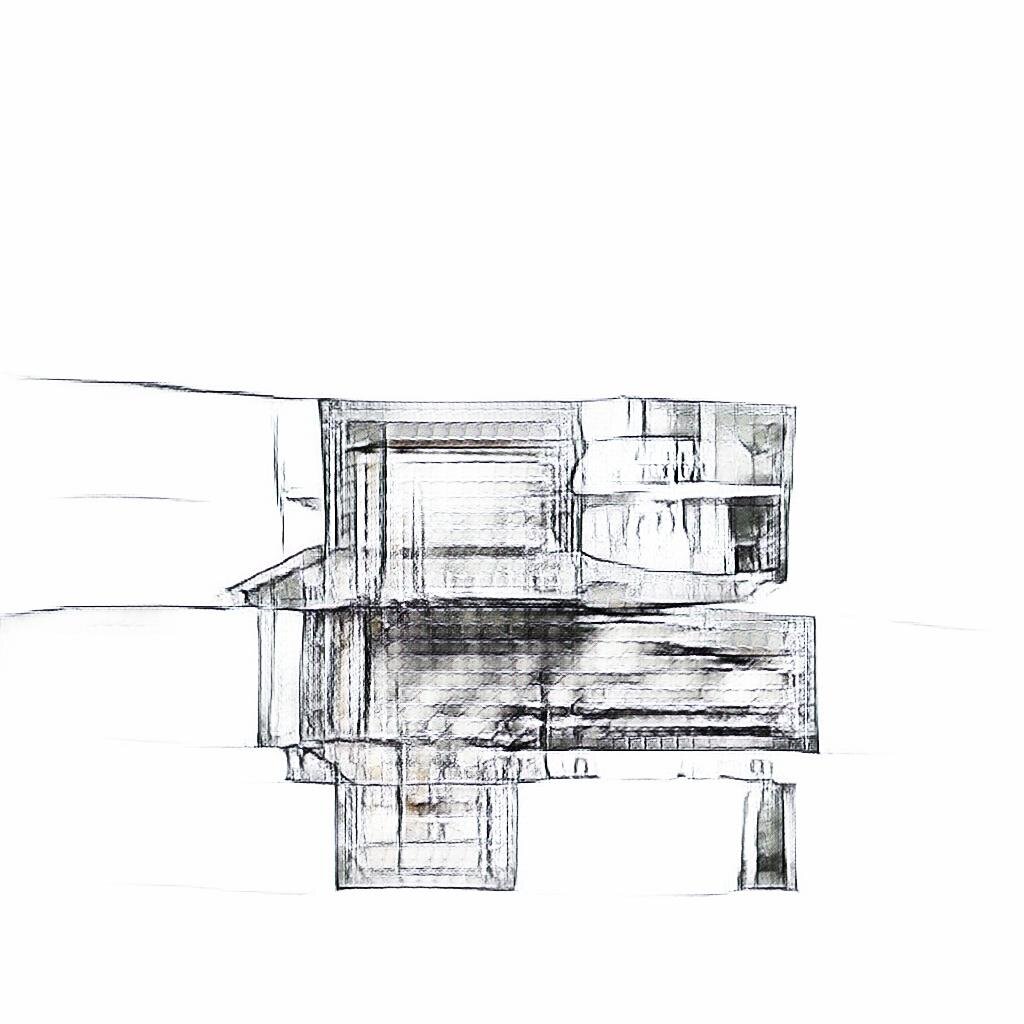



The architectural drawing dataset was very diverse, which wasn’t handled very well by the Pix2Pix model. The model was trained for roughly 48 hours before reaching a plateau, producing drawings similar to the examples above. I may have to try this again with a much more similar set of input images. Also, the U^2 Net mask is probably not an ideal input label for generating coherent drawings with Pix2Pix. I may be better off with canny edges or a depth map.